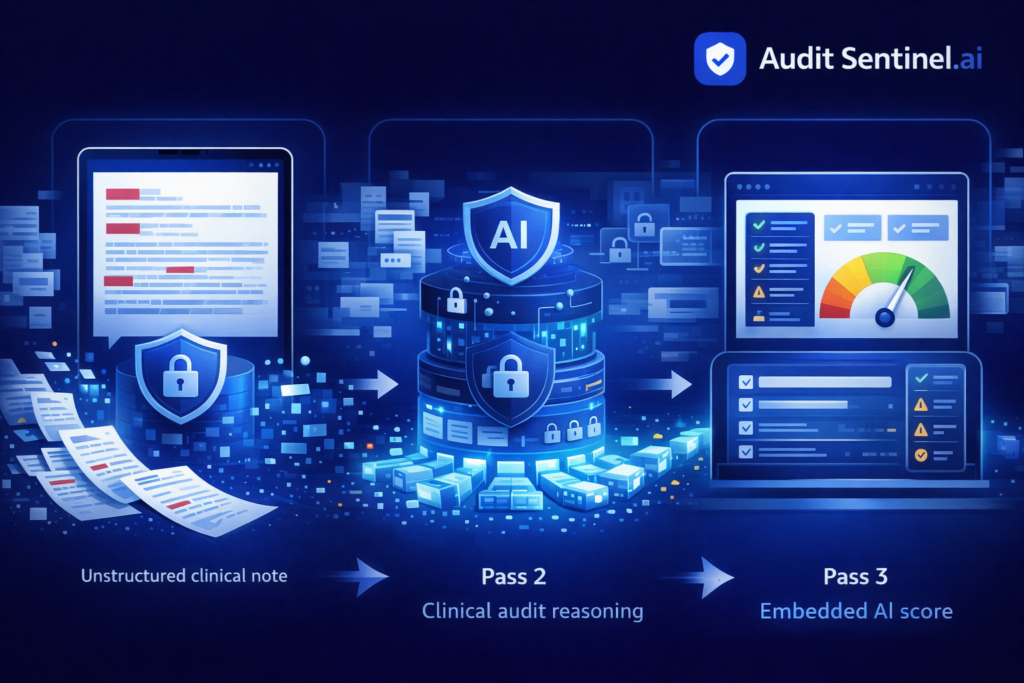
A look inside the three-pass AI pipeline that powers every audit
Every E/M audit starts the same way: a clinical note goes in, and a judgment about coding accuracy comes out. Traditionally that judgment takes a certified coder 15–20 minutes per note — reading the documentation, mapping it against the AMA’s MDM grid, cross-checking ICD-10 specificity, and comparing everything to the billed codes. Audit Sentinel compresses that cycle into seconds using a three-pass AI pipeline built on Google Cloud Vertex AI. The architecture isn’t a single model prompt that tries to do everything at once. It’s three distinct stages, each with a narrow job, running in sequence so that privacy, clinical accuracy, and grading logic never compete for the same inference call.
Pass 1 is the PHI Scrubber. Before any clinical reasoning begins, a fast frontier language model scans the raw note and redacts all 18 HIPAA Safe Harbor identifier categories — names, dates, SSNs, MRNs, device IDs, and everything in between. Each identifier is replaced with a standardized placeholder like [REDACTED_NAME] or [REDACTED_DATE]. The output is a de-identified note, and that de-identified note is the only version that moves forward. The raw text is held in volatile memory for the duration of Pass 1 and then discarded. No downstream pass — and no human at Audit Sentinel — ever sees the original PHI. This isn’t a feature bolted on after launch; it’s the first stage of every single audit, by design.
Pass 2 is the E/M and ICD-10 Auditor. A high-capability frontier reasoning model reads the de-identified note and performs a full clinical coding analysis: MDM complexity across all three elements (Problems, Data, Risk), time-based code selection where documented, ICD-10 validation for specificity and clinical support, modifier appropriateness, CCI bundling edits, and medical necessity linkage. The output is what we call the “ideal analysis” — the coding picture that the documentation supports, independent of what the provider actually billed. Pass 2 doesn’t know what was billed; it only knows what the note says. That separation is deliberate: it prevents anchoring bias, where a model might rationalize the submitted code instead of reading the chart on its own terms.
Pass 3 is the Billing Comparator and Grader. It takes the provider’s submitted codes and holds them against the Pass 2 ideal analysis, applying a fixed deduction table — not a subjective AI judgment — to produce a 0–100 numeric score and a letter grade from A to F. Over-coding deductions are intentionally steep (up to 35 points for a two-level over-code) because the compliance exposure is asymmetric: under-coding costs the provider revenue, but over-coding creates payer and regulatory risk. If the findings cross a severity threshold, a compliance flag is asserted, signaling that a qualified human should review the encounter before the claim goes out. The result is a structured JSON report with the score, the grade, every deduction itemized with a reason code, and a plain-language narrative — ready to hand to a compliance officer, drop into a trend dashboard, or export as a PDF for the audit file.
Audit Sentinel AI is an educational and advisory audit tool. It is not a substitute for a certified coder, licensed attorney, or payer determination. For methodology details, see our Audit Methodology White Paper.